Чтобы самостоятельно получить закодированную в QR код информацию, нужно, прежде всего знать алгоритм и этапы ее получения. Для каждого отдельного типа кодирования существуют свои этапы и порядок преобразования информации о которых мы расскажем в этой статье.
Для получения QR матрицы, то есть самого изображения QR-кода, состоящего из квадратных модулей, необходимо произвести преобразование исходной информации в QR код. QR-кодирование происходит в несколько этапов, ни один из которых нельзя пропустить или исключить из процесса шифрования. Чтобы не ошибиться с порядком кодирования, все этапы в статье пронумерованы. Каждый из них рассмотрен более подробно, для того чтобы лучше понять необходимость действий выполняемых в нем. После прочтения этой статьи, зная какой-либо из языков программирования, можно попробовать написать свой собственный алгоритм для создания QR-кода.
Этап 1. Выбор метода шифрования данных
Метод шифрования зависит от типа кодируемых символов. Иначе говоря, на этом этапе осуществляется выбор одного из типов кодирования.
- цифровой;
- буквенно-цифровой;
- байтовый;
- кандзи.
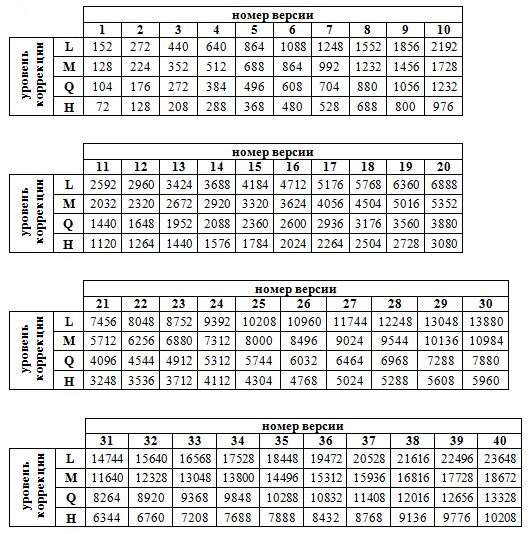
После этого выбирается версия кода, именно она определяет размер получаемого изображения. Минимальный размер – 21х21 пиксель - можно получить при использовании первой версии. Максимальный размер QR-кода – 177х177 пикселей – получается если используется 40-я версия.Чем выше версия, тем больше символов можно зашифровать. В размерностях версий не учитываются поля матрицы.
Этап 2. Выбор уровня коррекции ошибок
Коррекционные данные относятся к служебной информации, без которой не обходится ни один QR-код.В качестве кода коррекции используются различные вариации кодов Рида-Соломона, длина кодового слова в которых равняется 8.
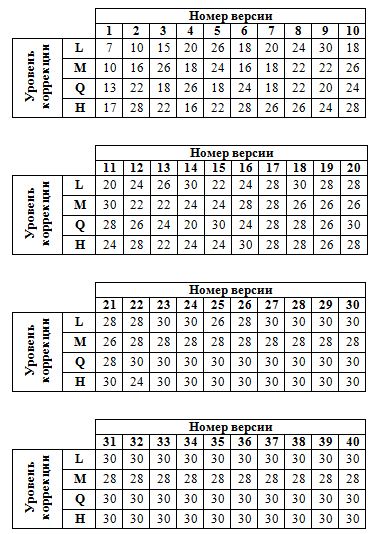
Существует 4 коррекционных уровня: L, M, Q и H.Каждый из нихимеет свое максимально допустимоеколичество повреждений изображения, выражаемое в процентах. При использовании уровня L, изображение может быть повреждено максимум на 7%от всей емкости, при Mи Q– 15 и 25 % соответственно. В случаях, когда к QR-изображению добавляется рисунок, рекомендуется применять наивысший коррекционный уровень – H, который сможет скорректировать до 30% поврежденного изображения.
У каждой версии QR-кода существуют свои наибольшие значения коррекционных уровней, выражаемые в количестве символов. Это связано с тем, что размерность матрицы имеет прямую зависимость от ее версии. Чем она выше, тем крупнее изображение, и тем большую площадь займут на нем закодированная информация и коррекционные данные. Максимальный объем полезных данных, в том числе служебных, можно узнать из специальных таблиц.
На этом же этапе записывается служебная информация. Она располагается перед закодированными символами, чтобы при считывании QR-кода, еще до прочтения закодированной информации, можно было узнать метод шифрования, и какое количество информации содержится в коде.
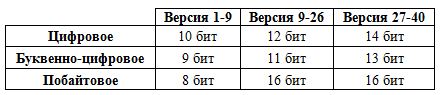
Количество информации представляется двоичным числом, длина которого зависит от версии и типа кодировки. Это число обозначает, сколько символов или байт зашифровано в коде.
Поле, предназначенное для добавления метода кодирования всегда имеет неизменную размерность 4 бита. Меняются только значения указываемые в нем, согласно которым определяется метод кодирования при считывании:
- 0001 –цифровое;
- 0010 – буквенно-цифровое;
- 0100 –побайтовое.
По завершению этого этапа, должна сформироваться битовая последовательность. Биты в ней должны быть расположены в таком порядке: метод шифрования, количество данных, зашифрованная информация.
Пример. При кодировании слова «Дом» побайтовым методом, в Unicode (HEX) в UTF-8, символы слова имеют значения:
- «Д» - D094;
- «о» - D0BE;
- «м» - D0BC.
При переводе полученных 16-ричных значений в 2-ичную систему счисления:
- D0=11010000;
- 94=10010100;
- D0=11010000;
- BE=10111110;
- D0=11010000;
- BC=10111100.
После объединения в единую последовательность, она будет иметь вид: 11010000 10010100 11010000 10111110 11010000 10111100. Этот двоичный код содержит 48 бит данных.
При необходимости использования уровня Q, позволяющего восстанавливать 25% данных, согласно таблицам для определения максимального количества полезных данных, самой оптимальной версией QR-кода будет первая версия (позволяющая зашифровать 104 символа полезных данных, при коррекционном уровне Q).
Так как в качестве метода кодирования был выбран побайтовый, то в поле метода кодирования будет стоять значение 0100. При переводе его в 2-ичную систему счисления, он станет выглядеть как 110 и содержать 6 байт информации.
Согласно таблице для определения длины 2-ичного числа, его длина должна быть 8 бит. Поэтому последовательность 110 превращается в 00000110, путем дописывания к ней нулей.
По завершению этих этапов, поток бит выглядит следующим образом: 0100 00000110 11010000 10010100 11010000 10111110 11010000 10111100
Этап 3. Разбиение битового потока на блоки
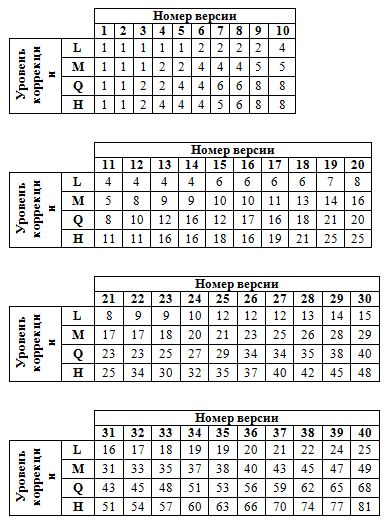
Полученный на втором этапе поток бит разделяется на блоки, в соответствии со специальной таблицей. Из нее берутся значения согласно выбранным версии и коррекционным уровнем.
Если блок оказывается всего один, данный этап можно считать пройденным. Если их два и больше, то необходимо добавить специальные блоки.
Вначале определяется, сколько данных (в байтах) находится в каждом отдельном блоке. Чтобы это сделать, следует поделить число всех байт на число полученных при разбиении блоков. Полученные в результате этой операции остаточные байты показывают число дополненных блоков(число байт в них на единицу больше чем в других). Такие блоки могут находиться в различных частях последовательности, в том числе ими могут оказаться последние блоки.
После этого все полученные блоки последовательно заполняются байтами данных. После полного заполнения одного блока, происходит переход к следующему блоку.
Например, при использовании 8 версии и коррекционного уровня H:
- число данных - 688 символов (по таблице для определения наибольшего количества полезных данных), или86 байт (1 символ это один бит данных, в одном байте – 8 бит).
- число блоков равно 6 (по таблице выбора числа блоков).
При делении 86 на 6 получится 14 байт и 2 остаточных. Следовательно, размер блоков в байтах 14, 14, 14, 14, 15, 15 (при без остаточном делении, размер всех блоков был бы по 15 байт).В полученные блоки заносятся данные.
Этап 4. Создание корректирующих байтов
После того, как исходные данные были разбиты на блоки, для них создаются корректирующие байты. Этот этап основывается она алгоритме Рида-Соломона, применяемого ко всем без исключения блокам данных (даже если был получен всего один блок).
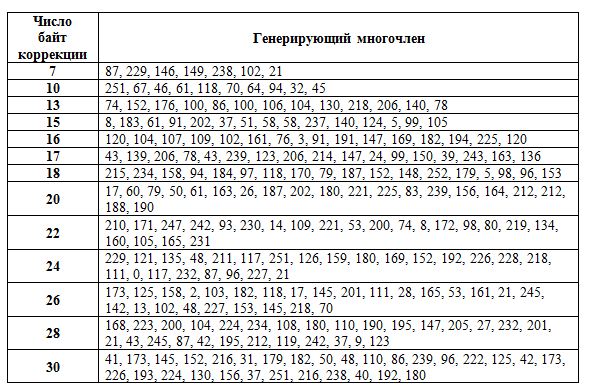
Из таблицы для определения числа корректирующих байт узнается, сколько таких байт понадобится создать. После этого создается генерирующий многочлен.
Для многочленов так же есть своя таблица. Каждое существующее число байт коррекции меет свой многочлен.
До того как начнется цикл создания байтов коррекции, подготавливается массив с длиной соответствующей максимальному числу байт в блоке. Байты блока заносятся в начало, а конец заполняется нулями.
Далее процедура повторяется до конца байт в блоке. По завершению всего цикла, каждый блок получит свои корректирующие байты.
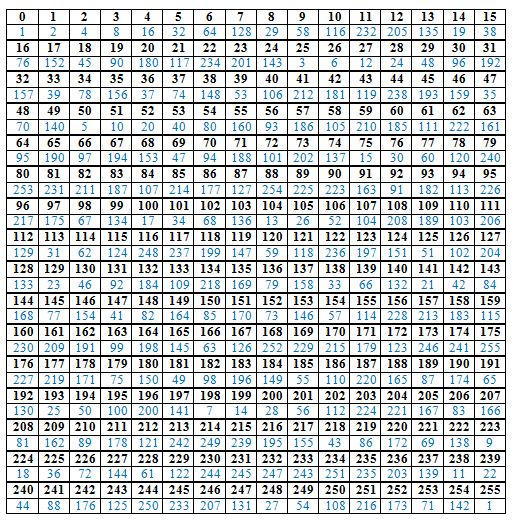
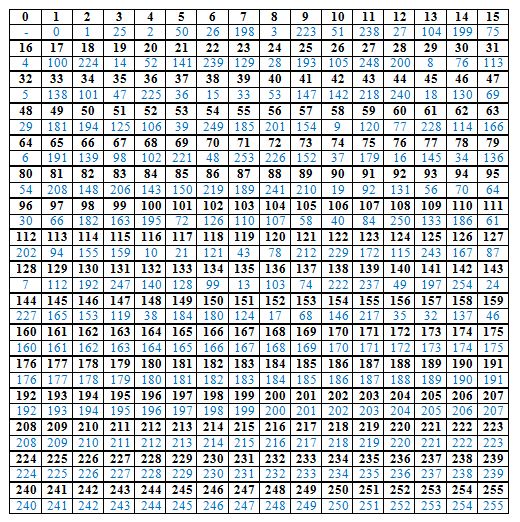
Так же для работы с массивами данных понадобятся таблицы со значениями для поля Галуа и обратного поля Галуа, длинами 256.
Подробная работа цикла описана в примере ниже, байты представлены в 10-ричной системе от 0 до 255.
В качестве примера взят произвольный исходный блок данных: 32 197 133 85 197, все байты которого представлены десятичными числами от 0 до 255.
Используемая версия – 1, с уровнем M. Число создаваемых корректирующих байт – 7, им соответствует многочлен генерации: 87, 229, 146, 149, 238, 102, 21.
Создается массив на 7 элементов, в него заносятся байты данных: 32 197 133 85 197 0 0.
Первое действие цикла.По таблице обратного поля Галуа находится соответствие для первого элементаблока. Числу 32 соответствует число 5, оно складывается по модулю 255со всеми членами многочлена:92 234 151 154 243 107 26.
Для получения результата такого сложения, нужно сложить числа, и если их сумма меньше модульного числа, то это и есть сумма по модулю. Если же больше, то сумма по модулю вычисляется как остаток от деления суммы чисел на модуль.
Например, сложение чисел 5 и 87 по модулю 255, записывается как: 5mod 255 + 87 mod 255 = (5+87) mod 255 = 92mod255 = 92. Так как 92 меньше чем 255, то это и есть искомая сумма.
Если бы по модулю 255 складывались числа 187 и 95, то запись была бы следующая: 187mod 255 + 95mod 255 = (187+95) mod 255 = 282 mod 255 = 27. Так как 282 больше 255, поделив первое число на второе, получим целочисленный остаток 27.
Для всех полученных в результате сложения чисел находятся соответствия в таблице поле Галуа: 91 251 170 57 125 104 6.
Элементы массива сдвигаются, к нему дописывается ноль (197 133 85 197 0 0 0) и побитово складывается по модулю 2 с членами массива: 158 126 255 252 125 104 6. Этот массив и есть корректирующие байты.
Далее цикл повторяется. Всего в цикле из этого примера должно быть 5 действий.
Побитовое сложение по модулю во многих языках программирования представляется операцией xor (исключающее или). Например, 197+91 будет записано как 197xor91. В битах будет выглядеть как 11000101xor1011011, что в сумме даст 10011110 или 158 в десятичном виде. Результат вычисляется согласно существующим соотношениям:
- 0+0=0;
- 0+1=1;
- 1+0=1;
- 1+1=0.
Этап 5. Объединение блоков данных
По завершению первых четырех этапов получается пара информационных блоков: блок исходных данных и данные коррекции. Они и объединяются в единый байтовый поток. Объединение, аналогично третьему этапу, носит цикличный характер.
Из первого блока берется 1 байт. Затем тоже самое делается во втором блоке. Действия повторяются, пока не закончатся все байты в последовательностях. После того, как взят байт из блока стоящего в самом конце, переходят обратно к первому.
Полученный массив байт выглядит следующим образом:
<первый байт первого БД><первый байт второго БД>…<первый байт n-го БД><второй байт первого БД>…<(m-1)-ый байт первого БД><(m-1)-ый байт n-го БД><m-ый байт k-го БД>…<m-ый байт n-го БД><первый байт первого БК><первый байт второго БК>…<первый байт n-го БК><второй байт первого БК>…<p-ый байт первого БК>…<p-ый байт n-го БК>
В его начале стоят байты исходных данных (БД), а в конце байты коррекции (БК).
Обозначения:
- n – число БД;
- m – число байтов на один БД;
- p – число БК;
- k–это то же n, только за вычетом числа БД имеющих на 1 байт больше.
Этап 6. Размещение байтов данных на матрице QR-кода
QR-матрица имеет обязательные поля и отступ. В них не содержится никакой зашифрованной информации. Эти поля служат для позиционирования и несут в себе данные необходимые для декодирования.
Поисковые узоры и отступ.
Любое QR-изображение имеет три поисковых узора, размерами 8х8 модулей каждый (один модуль – это один черный или белый квадрат), располагаемых в трех его углах (за исключением нижнего право). Поисковые узоры имеют квадратный вид, в центре размещается черный квадрат 3х3 модуля, его окружает белая и черная рамки (шириной в один модуль каждая). С внутренней стороны располагается еще половина белой рамки, так же шириной в 1 модуль. Для наглядности, поисковые узоры отмечены на картинке красным цветом.
Вокруг всей QR-матрицы проходит белая рамка (шириной 4 модуля). Поисковые узоры и рамка необходимы для успешного позиционирования изображения. Эти поля присутствуют на всех QR-кодах.
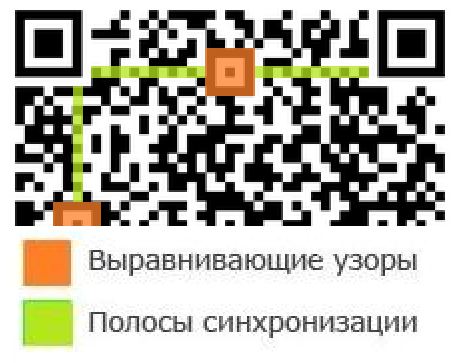
Выравнивающие узоры
Выравнивающие узоры имеются у всех версий QR-кода, кроме первой. Они служат в качестве дополнительного стабилизатора кода при его дешифрировании. Выравнивающих узоров может быть несколько, равно, как и не быть совсем (у кодов первой версии). Внешне они напоминают поисковый узор, только с размерами 5х5 модулей. Центромузора является единственный черный модуль, окруженный рамками обоих цветов (шириной в 1 модуль).
Полосы синхронизации
Так же имеются у всех версий кода. Эти полосы необходимы, чтобы определить модульный размер при считывании. Всего таких полосы две. Одна полоса находится между левым и правым поисковым узором, вторая между верхним и нижним левыми поисковыми узорами. Полосы синхронизации начинаются с черного цвета, затем цвета чередуются через один. Если на их пути попадаются выравнивающие узоры, то вид узора не меняется, а происходит его наслоение на полосу.
Код маски и уровня коррекции
Эти поля располагаются вдоль всех поисковых узоров. Поле, соприкасающееся с нижним краем верхнего правого узора идентично тому, что соприкасается с правым краем верхнего левого узора. Размеры этих полей 8 модулей. Точно так же идентичны поля соприкасающиеся с правым краем левого нижнего поискового узора и нижним краем левого верхнего узора. У них размеры 7 модулей.
Код версии тоже дублируется. С верхнего края правого поискового узора на левый край правого узора. Причем нижний код представляет собой копию того что снизу, только в зеркальном отображении иперевернутую на 90 градусов влево.
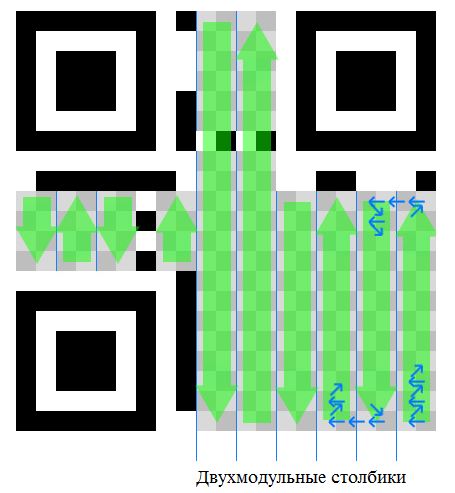
Оставшееся свободное место
Вся остальная поверхность изображения служит для занесения данных. Для этого свободное пространство разделяется на двухмодульные столбики. Начиная с правого нижнего угла матрицы, ее заполняют битами из байтов данных, двигаясь змейкой. Черные модули это единицы, а белые – нули. Первым будет правый нижний модуль, затем модуль слева от него, затем модуль над правым нижним, модуль над левым нижним и так далее, пока не дойдет до самого верха. От нее движение пойдет в обратном порядке – вниз, и затем опять вверх. И так пока не будет заполнено все пространство QR-матрицы.
При недостаточности данных, модули заполнятся нулями и останутся белыми (пустыми). На каждый модуль при размещении его на матрицу, накладываетсяодна из 8 масок:
- 0 – (А + В) % 2;
- 1 – В % 2;
- 2 – А % 3;
- 3 – (А + В) % 3;
- 4 – (А/3 + В/2) % 2;
- 5 – (А *В) % 2 + (А*В) % 3;
- 6 – ((А*В) % 2 + (А*В) % 3) % 2;
- 7 - ((А*В) % 3 + (А*В) % 2) % 2;
А обозначает столбец, В – строку, % - остаток от деления, / - целочисленное деление.
Если в результате вычисления выражение получается равным нулю, цвет модуля для которого производилось вычисление, изменяется. То есть, если изначально модуль был белого цвета, и в результате вычислений был получен ноль, то этот модуль станет черного цвета. Аналогично и для модулей с черным цветом.
Для каждого модуля выбирается своя оптимальная маска. Но нередко для упрощения ее делают единой для всех модулей.
Все вышеперечисленные этапы представляют собой алгоритм шифрования QR-кода, менять их последовательность нельзя, так как это приведет к не читаемости кода. Если все этапы пройдены верно, то в результате получается полноценный QR-код.
Читать дальше:

Основные возможности и структура QR-кода, необходимые для корректного шифрования и дешифрирования QR-изображений.

При грамотном использовании QR-код может стать отличным помощником в деле продвижения товара на рынке.

Бывают случаи, когда просто необходимо прочесть QR-код, а телефона с необходимым для прочтения приложением нет. Читаем QR-код самостоятельно.